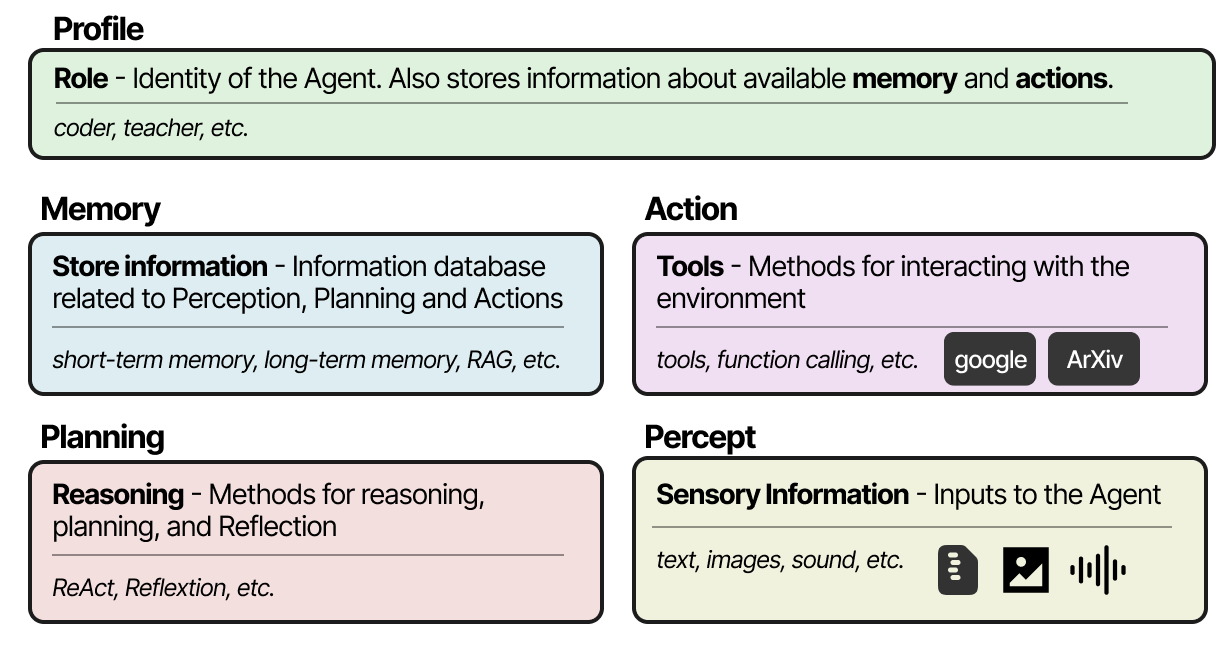
LLM Agents, or Language Model Agents, are advanced systems that enhance the capabilities of traditional conversational LLMs by integrating components like memory, tools, and planning. These agents can interact with their environment, use external tools (e.g., calculators, web search), and plan actions autonomously. Key components include short-term and long-term memory systems, tool use (e.g., function calling, Toolformer), and planning techniques like ReAct and Reflexion. Multi-Agent frameworks, such as Generative Agents and CAMEL, enable collaboration between specialized agents, each with unique tools and memory systems, to solve complex tasks. These advancements are driving the evolution of LLMs into more autonomous and capable systems.
2025-03-17
本文通过实战演示了如何利用 Claude 3.7 Sonnet 和 MCP 两大 AI 工具,仅用 10 个提示词,快速构建一个功能完善的全栈 Web 应用程序——理发店网站。项目涵盖了精美的前端展示页面、支持用户预约的后端服务以及便捷的管理后台。通过 Remix 框架 和 Supabase 数据库,结合 AI 的自动化代码生成和调试能力,大幅提升了开发效率。尽管 Claude 和 MCP 在开发速度和降低门槛方面表现出色,但仍需注意其稳定性和生成代码的微调需求。总体而言,AI 工具为全栈开发带来了革命性的效率提升。
2025-03-15
LangGraph Multi-Agent Swarm 是一个基于 LangGraph 的 JavaScript 库,用于创建群体风格的多代理系统。该系统允许具有不同专长的代理动态地将控制权交给彼此,并记住上次活跃的代理,以确保后续交互从该代理继续。主要功能包括多代理协作、自定义交接工具、流式处理、短期和长期记忆支持以及人工干预。通过安装相关库并配置代理工具,用户可以快速创建和定制多代理系统。库还支持短期和长期记忆的添加,确保对话状态的连续性。用户可以通过自定义交接工具或代理实现来进一步定制系统。
2025-03-10
Manus AI的邀请码一度被炒到天价,导致许多人无法体验。然而,开源界迅速反应,推出了无需邀请码的OpenManus项目,仅用3小时代码量就实现了Manus的核心功能。OpenManus由MetaGPT的核心贡献者开发,集成了多个顶级大模型,提供了模块化的Agent系统和强大的工具链,能够处理复杂任务并实时反馈。此外,OpenManus的Browser-use功能使AI能够直接操作浏览器,自动化执行网页交互。尽管OpenManus在细节上仍有改进空间,但它无疑为AI领域带来了新的可能性,打破了Manus的垄断。
2025-03-07
DeepSeek-R1标志着LLM进入深度思考时代,通过自我反思和验证提升了模型的推理能力,适用于复杂问题和日常场景。R1的创新包括R1-Zero、R1和蒸馏三部分,证明了数据决定上限、算法逼近上限的理念。R1-Zero通过纯规则强化学习(RL)展示了自我验证和反思的能力,而R1通过冷启动和RL进一步提升推理能力,并生成高质量数据用于微调。蒸馏则让小模型也具备推理能力。R1的影响不亚于ChatGPT的发布,重新定义了高质量数据和训练范式,推动了LLM向更人性化的方向发展。
.webp?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1cmwiOiJhc3NldHMvNjQwICg1KS53ZWJwIiwiaWF0IjoxNzQxMDQ2MjUzLCJleHAiOjE3NDM2MzgyNTN9.VQ3bI8FWs2QRQ8PwodTK-6Gi5QAtd36V_B2vrK1INYc)
2025-02-24
本文详细描述了作者如何通过提示词工程在Claude 3.5 Sonnet上模拟DeepSeek-R1的深度思考过程,使模型的推理过程更加透明化。作者首先分析了DeepSeek-R1的特点,即展示完整的推理过程后再给出答案,然后尝试在Claude上实现类似效果。通过多次优化提示词,作者最终成功让Claude按照指定的思考框架输出推理过程,并提供了额外的情绪价值,如撒娇、鼓励和emoji,提升了用户体验。文章还探讨了这种“复刻”的意义,强调了通过观察模型的思考过程,用户可以提升自己的沟通表达能力和逻辑思维能力。此外,作者指出,尽管DeepSeek-R1的出现改变了提示词工程的范式,但提示词工程依然具有重要价值,尤其是在个性化场景中。最后,作者总结了这次实践的启示,认为透明化的思考过程不仅有助于个人成长,还将在教育培训、决策支持等领域发挥重要作用。
2025-02-19
从2017年Transformer架构的引入到2025年DeepSeek-R1的推出,大型语言模型(LLMs)的发展标志着人工智能领域的革命性进步。Transformer架构为高效处理复杂任务奠定了基础,GPT-3展示了大规模模型的潜力,ChatGPT将对话式AI带入主流,而DeepSeek-R1则通过高性价比和开源特性,推动了AI技术的民主化和广泛应用。这一历程凸显了创新、规模化和可访问性在推动人工智能未来发展中的关键作用。
2025-02-17
DeepSeek-R1模型通过创新的MoE架构和MLA注意力机制等技术,实现了高效的训练和推理能力,并大幅降低了API调用成本,迅速成为AI圈的热门话题。尽管其7B和32B版本在本地部署中表现出一定的能力,但与“满血版”671B相比仍有显著差距,尤其是在语言生成、联网总结和代码能力方面。32B模型虽然性能接近671B,但本地部署的门槛较高,需要昂贵的硬件支持。对于普通用户而言,使用市面上的免费大模型产品可能更为便捷和经济。DeepSeek的成功不仅改变了技术竞争格局,还推动了全球科技创新合作,展示了人工智能在国际竞争中的重要性。
.webp?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1cmwiOiJhc3NldHMvNjQwICg0KS53ZWJwIiwiaWF0IjoxNzM5Njc3NTMxLCJleHAiOjE3NDIyNjk1MzF9.BY5VixVG1QS-jazgaCKlFyaRKnBEmYcE7sLL4YzEAxM)
2025-02-11
DeepSeek的崛起标志着中国AI行业从“参数崇拜”和“资本泡沫”向“效率革命”和“技术驱动”的转变。通过创新的强化学习与模型蒸馏技术,DeepSeek以极低的成本和高效的性能颠覆了传统大模型的竞争格局,打破了“模型越大越强”的行业共识。其开源策略和低成本API不仅重构了商业逻辑,还推动了AI技术的普惠化,瓦解了旧有的技术垄断和封闭生态。用户的选择和市场理性的回归进一步证明了技术实力才是核心竞争力。DeepSeek的成功为中国AI行业指明了一条新路:真正的竞争力源于底层创新和商业本质,而非资本堆砌或营销炒作。这场变革不仅揭示了伪强者的脆弱,也为行业的未来发展奠定了坚实基础。
2025-02-14
这篇文章介绍了如何通过飞书多维表格和DeepSeek R1结合AI工具,实现批量化、自动化的工作流,从而大幅提升工作效率。

2025-02-13
DeepSeek通过V3和R1模型展示了其在AI训练和推理领域的重大突破,尤其是极低的训练成本和高效率的推理能力,挑战了美国在AI领域的主导地位。其成功表明,芯片禁令并未阻止中国技术进步,反而推动了创新。AI模型的普及和商品化趋势将惠及消费者和企业,但也对OpenAI等公司构成威胁。文章呼吁美国放弃防御性策略,通过创新和竞争来应对挑战,而非依赖封锁和监管。
.webp?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1cmwiOiJhc3NldHMvNjQwICgxKS53ZWJwIiwiaWF0IjoxNzM5NDU3MjU5LCJleHAiOjE3NDIwNDkyNTl9.QwcGiHzEkhoaNzr0W70gH96C8pd8Agwr0F-thI8_Kzk)
2025-02-09
这篇博客探讨了在类 R1-Zero 训练中,模型自我反思行为的出现及其对性能的影响。研究发现,自我反思行为在基础模型(Epoch 0)中已经存在,并非通过强化学习(RL)训练后才出现。然而,许多自我反思是肤浅的(SSR),并不能有效提升答案的正确性。此外,模型响应长度的增加并非由自我反思直接引起,而是 RL 优化奖励函数的结果。研究表明,RL 训练的作用是将肤浅的自我反思转化为有效的反思,从而提升推理能力,而输出长度并不能可靠地反映自我反思的效果。
.webp?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1cmwiOiJhc3NldHMvNjQwICgyKS53ZWJwIiwiaWF0IjoxNzM5NDU4NDA2LCJleHAiOjE3NDIwNTA0MDZ9.ByHf9lT2h_y05aZcK9hyL26t6G7X7L9KEEi__sz64Dg)
2025-02-08
DeepSeek R1 671B 模型可以通过量化技术压缩体积,降低本地部署门槛。使用 ollama 在本地部署时,建议选择 Unsloth AI 提供的动态量化版本(如 1.73-bit 或 4-bit),并根据硬件条件调整参数。部署步骤包括下载模型文件、安装 ollama、创建 Modelfile 文件、创建并运行模型。1.73-bit 版本在轻量任务中表现良好,而 4-bit 版本更保守且稳定。硬件配置方面,建议内存+显存≥200GB(1.73-bit)或≥500GB(4-bit)。
.webp?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1cmwiOiJhc3NldHMvNjQwICgzKS53ZWJwIiwiaWF0IjoxNzM5NDU5MDE4LCJleHAiOjE3NDIwNTEwMTh9.uMOYdfhoPWmCb5FQ4BUKunfwTtRqnx7m5EbsbqELLU4)
2025-02-05